Análise Completa de Sitemap.xml e Erros no Labrika
Um arquivo Sitemap.xml é essencialmente um mapa do seu site projetado especificamente para facilitar a navegação e indexação do seu site pelos motores de busca. Ele está localizado dentro da sua pasta public_html (ou raiz do site) e inclui instruções importantes para os rastreadores dos motores de busca que especificam quais páginas devem ser visitadas, em que ordem e com que frequência visitá-las.
Isso acelera drasticamente o processo de indexação de páginas importantes e permite que os rastreadores aloque seu tempo de rastreamento para páginas de alta importância para você e seus usuários.
Criar um sitemap.xml nem sempre é necessário, mas sempre recomendado, especialmente para sites grandes com milhares de páginas. Com sites maiores, surge a necessidade de garantir que os rastreadores dos motores de busca gastem seu tempo nas páginas de alto valor com conteúdo profundo e intenção comercial, não em páginas laterais que oferecem pouco valor.
Como regra geral, quando softwares e CMSs geram automaticamente um arquivo sitemap.xml, eles incluem todas as páginas disponíveis para indexação. Um proprietário típico de site provavelmente não está ciente disso, e embora possa ter definido noindex para certas páginas, seus sitemaps gerados automaticamente provavelmente estão incluindo essas páginas e desperdiçando orçamentos de rastreamento valiosos!
É altamente recomendado usar plugins, software personalizado ou geradores de sitemap para configurar URLs específicas para mostrar no seu sitemap, certas URLs a serem evitadas, em que ordem rastrear URLs e com que frequência rastreá-las.
Erros de sitemap encontrados pelo Labrika
Atenção! O relatório de erros do sitemap só será acessível se permissões suficientes para escanear todo o site forem configuradas corretamente. Caso contrário, o Labrika só poderá visualizar páginas especificamente listadas no sitemap.xml, em vez de visualizar todas as páginas do site e compará-las com as páginas listadas no sitemap.
A análise de sitemap do Labrika ajuda a encontrar os seguintes tipos de erros:
-
Páginas que existem no sitemap, mas não são acessíveis para indexação.
-
Páginas que existem no sitemap mas têm uma tag noindex.
-
Páginas que não existem no sitemap, mas são indexáveis.
Observe: diferentes motores de busca processam regras de sitemap de maneiras diferentes. O Google, mais frequentemente, só indexará páginas que podem ser alcançadas por meio de rastreamento automático sem um sitemap. Ou seja, páginas que podem ser alcançadas via links internos dentro do tempo de rastreamento e profundidade de rastreamento alocados para o seu site naquele dia. Eles não olharão para o seu arquivo sitemap.xml para determinar quais links rastrear, mas em vez disso, usam o sitemap como um guia para com que frequência rastrear páginas listadas no sitemap.
Página existe no sitemap, mas não é acessível para indexação
Este relatório destaca principalmente páginas órfãs, que são essencialmente páginas que existem no seu site, mas não têm links de entrada apontando para elas e são 'sem dono'.
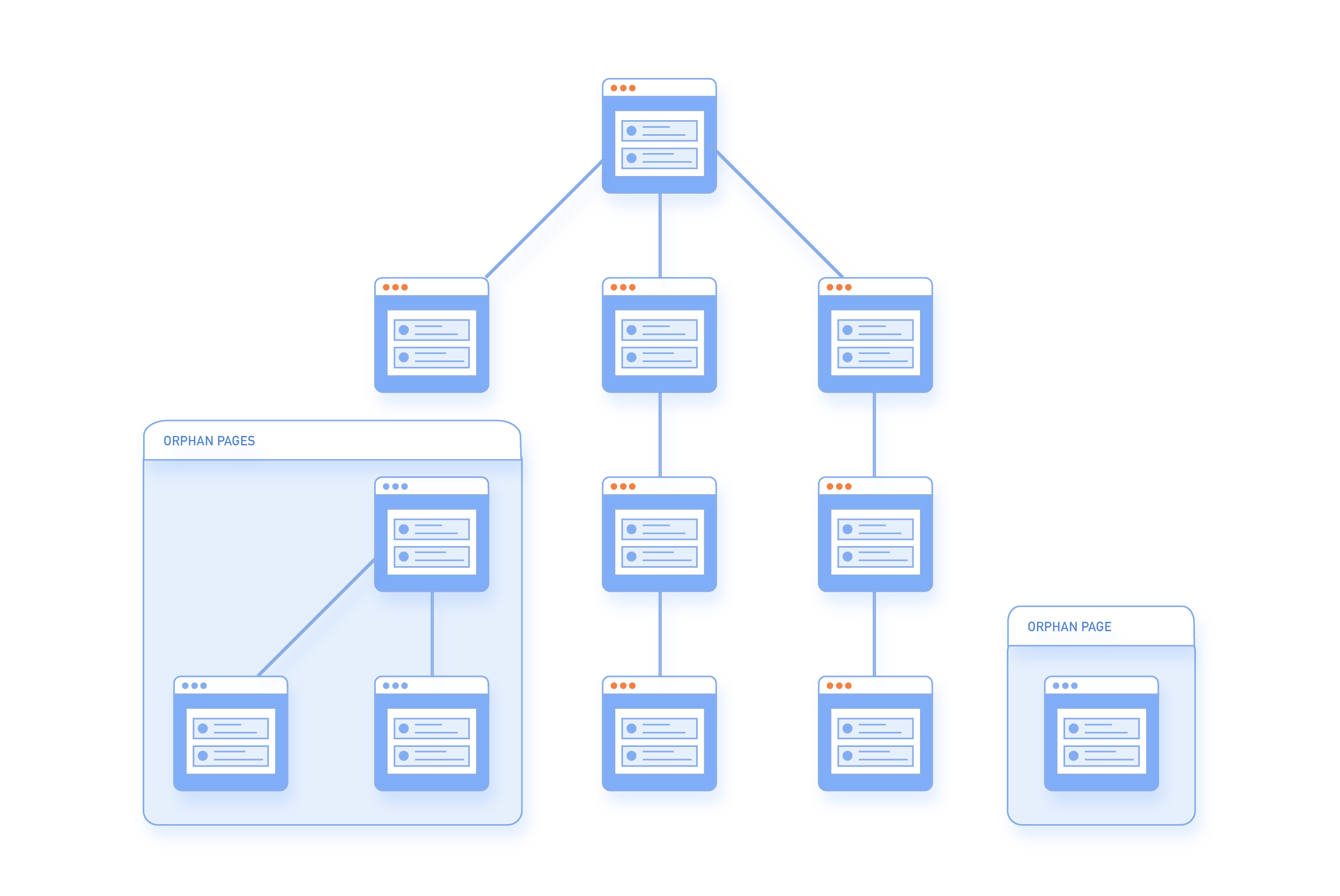
No caso de tais páginas serem de alguma forma indexadas pelos motores de busca, elas provavelmente terão PageRank zero e não se classificarão bem. Está bem documentado online que o Google e outros grandes motores de busca usam pontuações de PageRank (e suas várias formas) para determinar o poder de SEO e o valor das páginas. Foi apenas alguns anos atrás que o Google permitiu que você utilizasse uma barra de ferramentas que mostrava o PageRank das suas páginas, mas infelizmente, isso foi removido da esfera pública. Naturalmente, você quer bom PageRank para suas diferentes páginas, então se uma das suas páginas de destino acabar aparecendo nesta categoria de erro (ou seja, sua página não é apenas uma página órfã), então você vai querer chegar à fonte do problema imediatamente.
Razões comuns para sua página existir no sitemap, mas não ser acessível para indexação:
-
Um link de uma página/páginas com tag noindex leva a esta página, ou as páginas levando a esta página não respondem. Como resultado, o rastreador do motor de busca não pode avançar ou retroceder e, portanto, termina a sessão.
-
Links para as páginas necessárias estão bloqueados. Por exemplo, através do atributo rel="nofollow". Ou seja, o rastreador vê o link para a página, mas não pode navegar até ela porque é proibido.
-
Não há links para esta página e ela é verdadeiramente 'órfã'.
-
A página foi excluída no editor/CMS do site, mas o arquivo HTML ainda permanece ativo no site.
-
A página existe no sitemap, mas não é rastreável, então não pode ser indexada.
Esse tipo de erro é melhor retificado fazendo o seguinte;
Verifique quais páginas têm tags noindex e nofollow e corrija e/ou certifique-se de que a página seja adicionada corretamente ao menu principal para permitir o rastreamento correto. Além disso, mais frequentemente do que não, vemos esse tipo de erro com sites comerciais e informativos que bloqueiam paginação.
Como corrigir o problema?
Quando uma página está disponível no sitemap, mas não tem links internos de nenhuma outra página do site, ela é conhecida como uma página órfã.
Páginas órfãs são ruins para o SEO, pois não carregam peso de link e, portanto, são consideradas sem importância pelos motores de busca. Elas também foram usadas anteriormente no SEO black hat.
Uma vez identificadas no nosso painel, você pode:
- Reintegrar a página no esquema de links do seu site se a página for útil, classificar para palavras-chave ou ter backlinks de sites externos.
- Mesclar a página com outra se ela tiver uma página quase duplicada já vinculada no site.
- Remover a página inteiramente se ela não tiver uso. Ou retornar um código 404 ou 410 (conteúdo expirado).
- Para páginas de produto onde o item pode ter expirado, você pode vincular a novos produtos na mesma categoria, tornando a página uma nova fonte de leads. (Isso é o que o eBay faz com listagens de leilões expirados). Ajudando a gerar mais tráfego.
Página existe no sitemap, mas tem uma tag noindex
Estas são páginas que foram proibidas de indexação usando uma tag noindex, mas ainda existem em algum lugar no sitemap.
As pessoas colocam noindex em páginas por várias razões, mas ter páginas noindex listadas no sitemap pode levar a vazamentos de dados confidenciais, mas mais provavelmente, resulta em rastreadores desperdiçando seu tempo e orçamento de rastreamento.
Para corrigir este problema, você simplesmente precisa remover a página/páginas noindex do sitemap para evitar que qualquer motor de busca indexe inadvertidamente uma página que não deveria (embora eles normalmente sigam a tag noindex).
Como corrigir o problema?
Isso normalmente ocorre quando uma página foi bloqueada de indexação através de um atributo rel="nofollow".
Incluir essas páginas no sitemap não é útil, pois usa orçamento de rastreamento e poderia potencialmente levar ao vazamento de informações confidenciais. Para corrigir isso, você pode simplesmente remover a página do seu sitemap.
Baixe o arquivo sitemap.xml livre de erros do Labrika
Para cada um dos diferentes relatórios de erros de sitemap listados acima, o Labrika oferece a você a capacidade de baixar uma versão livre de erros e corrigida do seu arquivo sitemap.xml. Isso deve economizar seu tempo corrigindo seu próprio arquivo sitemap.xml manualmente e, o mais importante, fazer melhor uso dos seus orçamentos de rastreamento de motores de busca.
