O Que é Indexação
Indexação é o processo de análise de páginas do site (isso é normalmente realizado por motores de busca) e, em seguida, após o rastreamento, adicioná-las aos índices dos motores de busca. Esse índice (banco de dados) é então usado para formar resultados de busca, e também a classificação de páginas nos resultados de busca (após os algoritmos analisarem ainda mais as páginas com base na satisfação da intenção da consulta e no SEO bem-sucedido). A indexação é realizada por um crawler/robo do motor de busca.
Por Que Precisamos da Capacidade de Excluir Informações dos Índices dos Motores de Busca?
Como regra geral, informações que não devem ser exibidas nos resultados de busca podem ser bloqueadas dos índices dos motores de busca usando a tag “noindex” ou bloqueando o rastreamento de certas seções/páginas do site no arquivo robots.txt.
Páginas normalmente bloqueadas dos motores de busca são de natureza técnica, proprietária e confidencial, e são consideradas inadequadas para colocação nos resultados de busca.
Exemplos disso em um site comercial podem ser links apontando para; contas de usuários, carrinhos de compras, comparações de produtos, páginas duplicadas, resultados de busca no site e assim por diante!
Essas páginas são valiosas para os clientes e essenciais para a funcionalidade do site, mas não são úteis para os índices dos motores de busca.
Maneiras de Bloquear Páginas de Serem Indexadas pelos Motores de Busca
Há muitas maneiras de impedir a indexação de páginas:
-
Usando um arquivo robots.txt.
Robots.txt é um arquivo de texto que informa aos motores de busca quais páginas eles podem indexar e quais páginas não podem indexar.
Para bloquear uma página de ser indexada no robots.txt, você deve usar a diretiva Disallow.
Exemplo de um arquivo robots.txt que está permitindo a indexação de páginas de catálogo enquanto desautoriza a indexação do carrinho:
# O conteúdo do arquivo robots.txt, # que deve estar no diretório raiz do site # habilitar indexação de páginas e arquivos começando com '/catalog' Allow: /catalog # bloquear indexação de páginas e arquivos começando com '/cart' Disallow: /cart
-
Usando a tag <meta> robots com o atributo noindex.
Para bloquear uma página usando esse atributo, você precisa adicionar as seguintes linhas à seção
<head>da página:Para bloquear a página inteira da indexação, você deve colocar a seguinte linha no bloco
<head>da página em si:<meta name="robots" content="noindex">
-
Nofollowing links para que eles não indexem a página para a qual estão vinculando.
Há duas maneiras de fazer isso:
-
Bloqueando o crawler seguindo um link em uma base de link por link:
<a href="/page" rel="nofollow"> texto do link </a>
Lembre-se de que esse método só funcionará se cada link único para a página tiver o atributo “nofollow” nele. Se um link estiver faltando esse atributo, o crawler do motor de busca o seguirá e a página ainda será indexada.
-
Bloqueando o crawler seguindo qualquer link na página dando à própria página o atributo nofollow:
Ao adicionar a linha abaixo ao bloco
<head>na página, o crawler será bloqueado de seguir a página e, portanto, quaisquer links contidos na página não serão indexados.<meta name="robots" content="nofollow" />
-
-
Você também pode bloquear a página de ser rastreada por qualquer motor de busca específico no cabeçalho da página HTML, por exemplo:
Você pode colocar essa linha no bloco
<head>na página em si; isso bloqueará a página de ser indexada pelo Google (já que você bloqueou completamente o crawler deles):<meta name="googlebot" content="noindex">
Você também pode optar por “noindex” uma página específica enquanto permite que o Google siga os links nessa página, e então indexe as páginas sendo vinculadas da página “noindex”:
<meta name="googlebot" content="noindex, follow">
-
Página canônica.
O atributo rel=canonical é usado para indicar ao motor de busca que a página é uma página canônica (a mais autoritária). Isso indica ao crawler que essa é a página preferida para indexar e é o exemplo mais autoritário desse conteúdo no site deles.
Especificar páginas canônicas é necessário para evitar que páginas com conteúdo idêntico sejam indexadas, o que pode então prejudicar a classificação da página no SERP.
Você usaria esse atributo quando tiver várias páginas com conteúdo idêntico, mas com URLs diferentes para diferentes dispositivos:
https://example.com/news/https://m.example.com/news/https://amp.example.com/news/
Ou quando há várias opções de ‘classificação’ disponíveis para a página que alterarão a URL da página, mas mostrarão o mesmo conteúdo:
https://example.com/catalog/https://example.com/catalog?sort=datehttps://example.com/catalog?sort=cost
Ou se o link especifica os diferentes tamanhos de um determinado produto dentro da URL:
https://example.com/catalog/shirthttps://example.com/catalog/shirt?size=XLhttps://example.com/catalog/shirt38
O atributo rel=canonical é aplicado da seguinte forma:
<link rel=canonical href="https://example.com/catalog/shirt" />
Nota: você deve colocar esse atributo no bloco
<head>da páginaÉ também possível inserir a página canônica desejada no cabeçalho da solicitação HTTP.
No entanto, tenha cuidado, pois sem o uso de plugins especiais para seu navegador, você não poderá determinar se esse atributo foi definido corretamente, pois a maioria dos navegadores não mostra cabeçalhos HTTP aos seus usuários.
HTTP / 1.1 200 OK Link: <https://example.com/catalog/shirt>; rel=canonical
Você pode ler mais sobre páginas canônicas na documentação do Google.
-
Usando o cabeçalho de solicitação HTTP "X-Robots-Tag" para um URL específico:
HTTP / 1.1 200 OK X-Robots-Tag: google: noindex
Tenha cuidado, pois sem o uso de plugins especiais para seu navegador, você não poderá determinar se esse atributo foi definido corretamente, pois a maioria dos navegadores não mostra cabeçalhos HTTP aos seus usuários.
Como Encontro Páginas que Foram Bloqueadas de Indexação no Meu Site?
Você pode visualizar essas informações na seção "Auditoria SEO" - "Páginas bloqueadas de indexação" do seu painel Labrika.
Na página do relatório, você pode filtrar os resultados para ver quaisquer páginas de destino que foram bloqueadas de indexação. Para fazer isso, você precisa clicar no botão “erro crítico”.
Normalmente, quando um crawler de motor de busca visita seu site, ele rastreará todas as páginas que puder encontrar via links internos e então as indexará de acordo.
O objetivo desse relatório é mostrar quaisquer páginas que foram bloqueadas de serem indexadas. Essas tendem a ser páginas que não têm palavras-chave nos 50 principais resultados de busca, e podem ter sido intencionalmente bloqueadas de indexação por motores de busca por você.
Relatório “Páginas Bloqueadas de Indexação” do Labrika
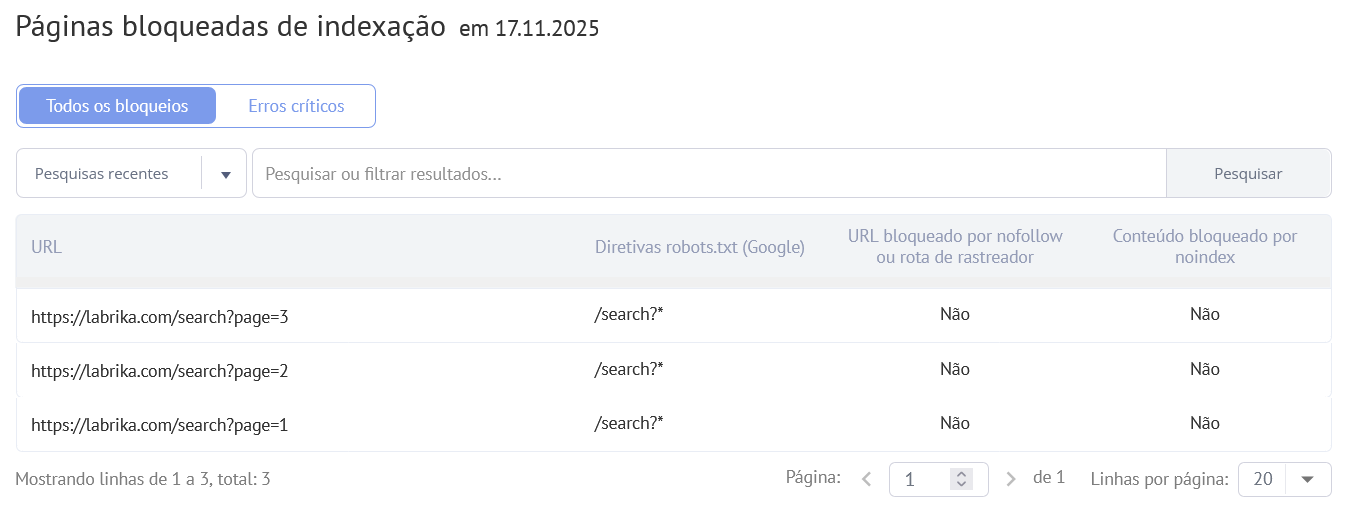
- O URL de quaisquer páginas que estão bloqueadas de indexação atualmente.
- A diretiva no robots.txt que está bloqueando a indexação para essa página (se a página estiver bloqueada de indexação no Google por esse método).
- Se essa página foi bloqueada via o atributo nofollow.
Como Paro uma Página de Ser Noindexed que Está Hospedada Nesse Relatório?
Em muitos sistemas de gerenciamento de conteúdo modernos (CMS), você pode alterar o arquivo robots.txt, rel= canonical, tag meta "robots", atributos “noindex” e “nofollow”. Portanto, para tornar uma página indexável novamente que está contida nesse relatório, você só precisaria remover o atributo/tag causando que essa página não seja indexada. Há muitos plugins simples que permitem fazer isso. Se você não conseguir alterá-lo sozinho, seria uma tarefa relativamente simples terceirizar para um desenvolvedor.