Validador Robots.txt: Guia Completo para Evitar Erros e Otimizar SEO
Robots.txt é um arquivo de texto que contém instruções (diretivas) para a indexação das páginas do site. Usando este arquivo, você pode informar aos robôs de busca quais páginas ou seções de um recurso web devem ser rastreadas e inseridas no índice (banco de dados do motor de busca) e quais não devem.
O arquivo robots.txt está localizado na raiz do site e pode ser acessado em domain.com/robots.txt.
Por que o robots.txt é necessário para SEO?
Este arquivo fornece aos motores de busca instruções essenciais que influenciam diretamente a eficácia do posicionamento de um site no motor de busca. Usar o robots.txt pode ajudar a:
- Impedir a varredura de conteúdo duplicado ou páginas não úteis para os usuários (como resultados internos de busca, páginas técnicas etc.) pelos rastreadores dos motores de busca.
- Manter a confidencialidade de seções do site (por exemplo, você pode bloquear o acesso a informações do sistema no CMS);
- Evitar sobrecarga do servidor;
- Gastar efetivamente seu orçamento de rastreamento em páginas valiosas.
Por outro lado, se o robots.txt contiver erros, os motores de busca poderão indexar o site incorretamente, e os resultados da busca incluirão informações erradas.
Você também pode, acidentalmente, impedir a indexação de páginas úteis que são necessárias para o posicionamento do seu site nos motores de busca.
Abaixo estão links para instruções sobre como usar o arquivo robots.txt do Google.
Conteúdo do relatório "Erros do Robots.txt" no Labrika
É isso que você encontrará no nosso relatório "erros do robots.txt":
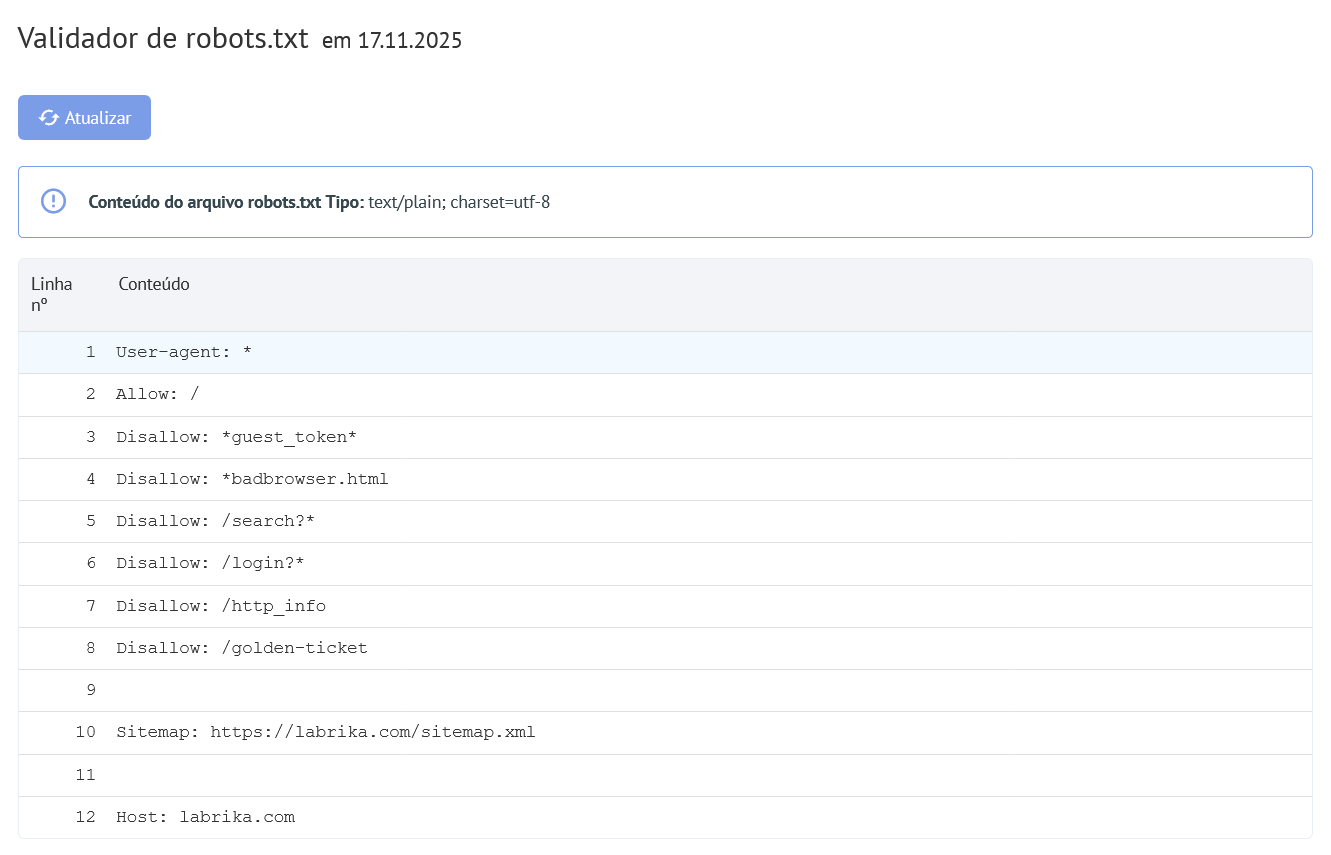
- Botão "Atualizar" - ao clicar, os dados sobre os erros no arquivo robots.txt serão atualizados.
- O conteúdo do arquivo robots.txt.
- Se um erro for encontrado, o Labrika fornece a descrição do erro.
Erros do robots.txt que o Labrika detecta
A ferramenta encontra os seguintes tipos de erros:
A diretiva deve ser separada da regra pelo símbolo ":"
Cada linha válida no seu arquivo robots.txt deve conter o nome do campo, dois pontos e o valor. Espaços são opcionais, mas recomendados para melhor leitura. O símbolo de cerquilha "#" é usado para adicionar um comentário, que deve ser colocado antes do início do comentário. O robô do motor de busca ignorará todo o texto após o símbolo "#" até o final da linha.
Formato padrão:
<campo>:<valor><#comentário-opcional>
Exemplo de erro:
User-agent Googlebot
Faltando o caractere ":".
Opção correta:
User-agent: Googlebot
Diretiva vazia e regra vazia
Usar uma string vazia na diretiva user-agent não é permitido.
Esta é a diretiva principal que indica para qual tipo de robô de busca as regras de indexação seguintes são escritas.
Exemplo de erro:
User-agent:
Nenhum user-agent especificado.
Opção correta:
User-agent: nome do bot
Por exemplo:
User-agent: Googlebot User-agent: *
Cada regra deve conter pelo menos uma diretiva "Allow" ou "Disallow". Disallow fecha uma seção ou página para indexação. "Allow", como o nome indica, permite que páginas sejam indexadas. Por exemplo, permite que um rastreador acesse um subdiretório ou página em um diretório que normalmente está bloqueado para processamento.
Essas diretivas são especificadas no formato:
diretiva: [caminho], onde [caminho] (o caminho para a página ou seção) é opcional.
No entanto, os robôs ignoram as diretivas Allow e Disallow se você não especificar um caminho. Nesse caso, eles podem rastrear todo o conteúdo.
Uma diretiva vazia Disallow: equivale à diretiva Allow: /, significando "não negar nada".
Exemplo de erro na diretiva Sitemap:
Sitemap:
O caminho para o sitemap não está especificado.
Opção correta:
Sitemap: https://www.site.com/sitemap.xml
Não há diretiva User-agent antes da regra
A regra deve sempre vir após a diretiva User-agent. Colocar uma regra antes do primeiro nome de user-agent significa que nenhum rastreador a seguirá.
Exemplo de erro:
Disallow: /category User-agent: Googlebot
Opção correta:
User-agent: Googlebot Disallow: /category
Uso da forma "User-agent: *"
Quando vemos User-agent: *, isso significa que a regra é definida para todos os robôs de busca.
Por exemplo:
User-agent: * Disallow: /
Isso proíbe todos os robôs de busca de indexar o site inteiro.
Deve haver apenas uma diretiva User-agent para um robô e apenas uma diretiva User-agent: * para todos os robôs.
Se o mesmo user-agent tiver diferentes listas de regras especificadas várias vezes no arquivo robots.txt, será difícil para os robôs de busca determinar quais regras considerar. Como resultado, o robô não saberá qual regra seguir.
Exemplo de erro:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf
Opção correta:
User-agent: * Disallow: /category Disallow: /*.pdf
Diretiva desconhecida
Foi encontrada uma diretiva que não é suportada pelo motor de busca.
As razões podem ser as seguintes:
- Uma diretiva inexistente foi escrita;
- Foram cometidos erros de sintaxe, uso de símbolos e tags proibidos;
- Essa diretiva pode ser usada por outros robôs de motores de busca.
Exemplo de erro:
Disalow: /catalog
A diretiva "Disalow" não existe. Houve um erro na grafia da palavra.
Opção correta:
Disallow: /catalog
O número de regras no arquivo robots.txt excede o máximo permitido
Os robôs de busca processarão corretamente o arquivo robots.txt se seu tamanho não exceder 500 KB. O número permitido de regras no arquivo é 2048. Conteúdo acima desse limite é ignorado. Para evitar ultrapassá-lo, use diretivas mais gerais ao invés de excluir cada página individualmente.
Por exemplo, se você precisa bloquear a varredura de arquivos PDF, não bloqueie cada arquivo individualmente. Em vez disso, bloqueie todas as URLs que contenham .pdf com a diretiva:
Disallow: /*.pdf
Regra excede o comprimento permitido
A regra não deve ter mais que 1024 caracteres.
Formato incorreto da regra
Seu arquivo robots.txt deve estar codificado em UTF-8 em texto simples. Os motores de busca podem ignorar caracteres que não sejam UTF-8. Nesse caso, as regras do arquivo robots.txt não funcionarão.
Para que os robôs de busca processem corretamente as instruções no arquivo robots.txt, todas as regras devem ser escritas seguindo o Padrão de Exclusão de Robôs (REP), que é suportado pelo Google e pela maioria dos motores de busca conhecidos.
Uso de caracteres nacionais
O uso de caracteres nacionais é proibido no arquivo robots.txt. Segundo o sistema de nomes de domínio aprovado pelo padrão, um nome de domínio pode conter apenas um conjunto limitado de caracteres ASCII (letras do alfabeto latino, números de 0 a 9 e hífen). Se o domínio contiver caracteres não ASCII (incluindo alfabetos nacionais), ele deve ser convertido para Punycode para um conjunto válido de caracteres.
Exemplo de erro:
User-agent: Googlebot Sitemap: https: //bücher.tld/sitemap.xml
Opção correta:
User-agent: Googlebot Sitemap: https://xn-bcher-kva.tld/sitemap.xml
Pode ter sido usado um caractere inválido
O uso dos caracteres especiais "*" e "$" é permitido. Eles especificam padrões de endereço ao declarar diretivas para que o usuário não precise escrever uma lista grande de URLs finais para bloquear.
Por exemplo:
Disallow: /*.php$
proíbe a indexação de qualquer arquivo PHP.